The Shapes of Knowledge

From spoken word to knowledge graphs
Genesis
In the beginning was the word
- John 1:1
Throughout history Knowledge was shared through speech. Songs, poems and stories. With a teller and it’s listener, a master and it’s apprentice.
Knowledge was local, it’s fidelity was vulnerable to the fallible human memory, and simply inaccessible if you didn’t directly interacted with someone who knew.
Necessity is the mother of invention
- Plato
Thus Necessity, gave birth to The Written Text.
What Plato didn’t tell you, is that each solution creates newer problems.
Wait… How do we organise all these books now?
- Someone somewhere a while ago
And we began experimenting with grouping, labelling and inventories…
 The Library of Alexandria being the earliest known example, ~250 BC.
The Library of Alexandria being the earliest known example, ~250 BC.
But with books neatly organized in categories, knowledge is stale. And emergent practices such as the Commonplace Book weave connections.
 Sir Isaac Newton (1642–1727) kept this pocket-sized “memorandum book”, filling it with notes distilled from his reading.
Sir Isaac Newton (1642–1727) kept this pocket-sized “memorandum book”, filling it with notes distilled from his reading.
By extracting, combining, and annotating knowledge from diverse sources, one could create personalized webs of information.
 Slime mold
Slime mold solving complex network optimization problems
Digital Redux
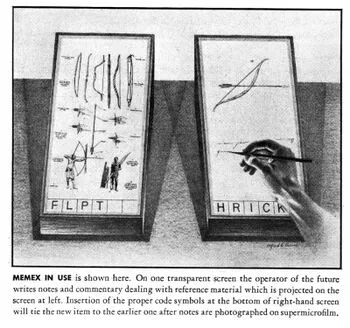 In “As We May Think”, 1945, Vannevar Bush describes a memex (from “memory expansion”) as an electromechanical device enabling individuals to develop and read a large self-contained research library, create and follow associative trails of links and personal annotations, and recall these trails at any time to share them with other researchers. This device would closely mimic the associative processes of the human mind, but it would be gifted with permanent recollection.
In “As We May Think”, 1945, Vannevar Bush describes a memex (from “memory expansion”) as an electromechanical device enabling individuals to develop and read a large self-contained research library, create and follow associative trails of links and personal annotations, and recall these trails at any time to share them with other researchers. This device would closely mimic the associative processes of the human mind, but it would be gifted with permanent recollection.
Thus science may implement the ways in which man produces, stores, and consults the record of the race.
- Vannevar Bush
 [Ted Nelson, transclusions, 1980. expand or remove … ?]
[Ted Nelson, transclusions, 1980. expand or remove … ?]
Challenge
How would you represent knowledge?
Imagine the following scenario:
Bob is a person born on July 14th, 1990. Bob is friends with Alice.
If you are a programmer or ever used a spreadsheet you may be tempted represent it in a table:
Person table
| ID | Name | Birthdate |
|---|---|---|
| 1 | Bob | 14 July 1990 |
| 2 | Alice | 1 January 1991 |
Friendship table |
| Person ID | Friend ID |
|---|---|
| 1 | 2 |
| Relationships feel awkward represented in tables, but let’s continue with our example: |
Bob loves The Mona Lisa, The Mona Lisa was created by Leonardo Da Vinci.
Artwork table
| ID | Title | Creator ID |
|---|---|---|
| 1 | The Mona Lisa | 3 |
Person table |
| ID | Name | Birthdate |
|---|---|---|
| 1 | Bob | 14 July 1990 |
| 2 | Alice | 1 January 1991 |
| 3 | Leonardo Da Vinci | 15 April 1452 |
Interest table |
| Person ID | Interest Type | Interest ID |
|---|---|---|
| 1 | Artwork | 1 |
| And that’s how Alien a few simple relationships become when represented in tables. |
Now let me enlighten you:
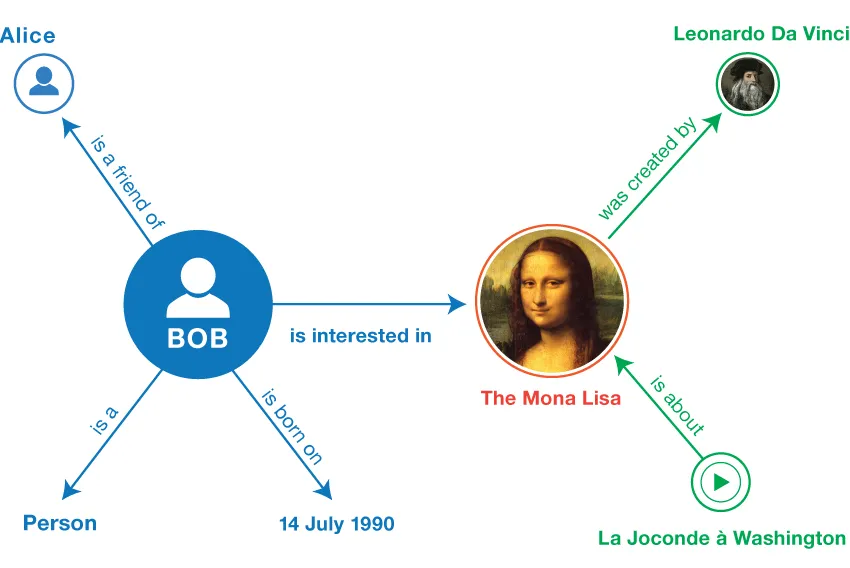
Graphs are the right substrate to represent Knowledge, because Knowledge is not just entities, but their relationships.
However, reality, is dynamic. Facts hold true for specific durations.
Knowledge is Multi-Dimensional
Why Knowledge Graphs are not enough
[Follow up on the example above with Bob works on ACME from]
Simply embedding temporal attributes like valid_from or valid_to onto nodes and edges, while functional, feels like an insufficient compromise. It clutters the graph’s topology, complicates queries, and treats time as an afterthought rather than a fundamental aspect of the knowledge itself.
This points towards a need for a paradigm shift. Instead of viewing time (and potentially space) as mere properties within the graph, we should consider them as fundamental dimensions upon which the graph exists or activates. Imagine a base graph defining potential entities and relationship types – the structural blueprint. Then, imagine a separate, but tightly coupled, Time dimension. The core idea is that connections within the graph blueprint are not inherently persistent; they become active or instantiated only during specific intervals along this Time dimension.
In this model, a relationship like “Alice WORKS_FOR Acme” wouldn’t exist as a single edge burdened with date properties. Instead, the potential WORKS_FOR link between Alice and Acme would be activated on the Time axis from, say, 2018 to 2022. This activation data forms the crucial linkage between the graph’s topology and its temporal context. Exploring the graph “at” time T means viewing the blueprint through the lens of linkages active at that specific point or interval. This conceptually mirrors ideas like Bitcoin’s “TimeChain,” where the chain’s progression validates transactions (relationships) over time.
Such an approach promises significant conceptual clarity. It separates the what (the structure) from the when (its temporal validity), preventing the core graph model from becoming bloated with metadata. Queries inherently become dimensionally aware (“Show connections at time T”). Snapshots become natural query results, not necessarily stored duplicates. This requires a different architectural foundation, likely leaning on principles like event sourcing (logging changes as timestamped events) or layered/delta storage mechanisms where the state at any time T can be reconstructed or queried efficiently, rather than navigating complex properties within a monolithic graph state.
While Time and Space feel like primary candidates for such dimensional treatment, the concept invites reflection on what constitutes a fundamental dimension of knowledge. Perhaps Provenance (“according to whom?”) could be another. Furthermore, dynamic qualities like “confidence” or “relevance” might not be static dimensions but could emerge organically, perhaps derived from usage patterns over time – connections strengthening or fading based on their “liveness” within the evolving knowledge ecosystem, adding another dynamic layer atop the dimensional structure.
Treating dimensions as fundamental axes rather than embedded attributes represents a more honest and potentially more powerful way to model dynamic knowledge. It acknowledges that facts are contextual and change is inherent. While posing significant architectural and implementation challenges, this vision pushes beyond the limitations of current property graphs towards a future where knowledge representation truly embraces the dynamism of the reality it seeks to model.
Questions for Further Exploration:
Beyond Time and Space, what truly qualifies as a fundamental “dimension” of knowledge, distinct from descriptive properties or derived metrics?
What are the most efficient underlying storage and indexing mechanisms (event sourcing, layered deltas, bitemporal indexing) to realize querying across graph topology and multiple dimensions (e.g., time and space) without prohibitive computational cost?
How should conflicts be handled when different dimensional contexts (e.g., information from different sources or valid at overlapping times) present contradictory graph structures?
Can the concept of “organic confidence” derived from usage patterns be formalized and integrated effectively alongside structural dimensions like time?
What query language paradigms best express navigating knowledge simultaneously across its structural connections and its dimensional context?